Shreshth Rajan, June 2026.
A search agent reads observations and acts: it issues queries, reads results, calls tools, and decides what to do next. We build these agents by taking a model trained to continue text and teaching it, in post-training, to take actions. Two failures keep showing up, and the literature treats them as separate problems.
The first: long-horizon agents degrade after a handful of turns even when every fact they need is already in their context. Recent diagnostics put the turn ceiling at three to seven steps across search, coding, and tool use [1], and catalog horizon-dependent breakdowns across model families [2]. The second: scaling test-time search saturates. You sample more candidates, the correct one appears more often, and the agent still fails to pick it [3, 4].
This post makes the case that both stem from one design choice. A search agent is solving a partially observed problem, a POMDP, and a POMDP solver needs two learned objects: a belief state, the agent's estimate of what is currently true, and a value, an estimate of how good a state or candidate is. Current agents have neither as a learned object; they substitute the raw transcript for the belief state and their own output probability for the value. Two controlled experiments below show that each substitute fails in a measurable way that worsens with horizon, and they point to the same fix: learn the missing object instead of faking it after the fact.
In a POMDP the agent never sees the state directly. It sees observations \(o_1, o_2, \dots\) and must maintain a sufficient statistic of the history. That statistic is the belief state, and it is maintained by a recurrent update,
$$b_t = f(b_{t-1}, o_t),$$a fixed-size estimate refined as each observation arrives, at constant cost per turn. Every result on planning or value estimation under partial observability is stated relative to the belief state, because an action is only as good as the state estimate it conditions on. A transcript-conditioned agent does something different. It draws
$$a_t \sim \pi(\cdot \mid o_1, \dots, o_t),$$re-reading the entire observation history at every step and re-solving the state-estimation problem from scratch. The cost grows linearly in the horizon, and the model has to recover the current state from a transcript that gets longer and noisier as the episode runs.
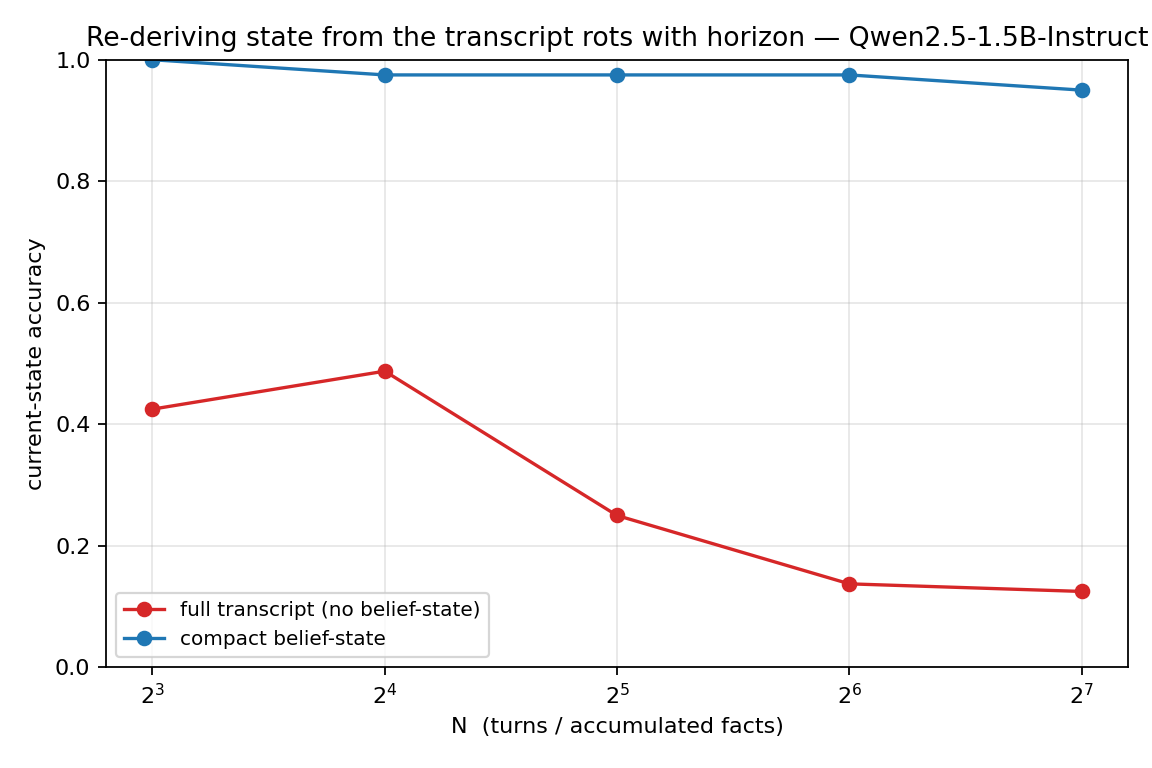
To measure the cost of that re-derivation I built a task that isolates state tracking from everything else. Four entities each have a location. Facts arrive in order, some overwriting earlier ones; the query asks for an entity's current location, and that entity's last update is placed early so distractor updates follow it. Reading the most recent fact does not work; the agent has to know the current state. I compare two ways of answering with the same model (Qwen2.5-1.5B-Instruct):
# Same model, same facts, same information. Only the state representation differs.
def answer_transcript(model, facts, query): # re-derive state every turn
ctx = "\n".join(facts) # context grows linearly in N
return model(f"Facts:\n{ctx}\nQ: {query}")
def answer_belief(model, facts, query): # carry a compact belief state
state = init_state() # fixed size, ~20 tokens
for fact in facts: # one O(1) update per turn
state = model(f"State:\n{state}\nUpdate: {fact}\nRewrite the full state.")
return model(f"State:\n{state}\nQ: {query}") # answer never sees the transcript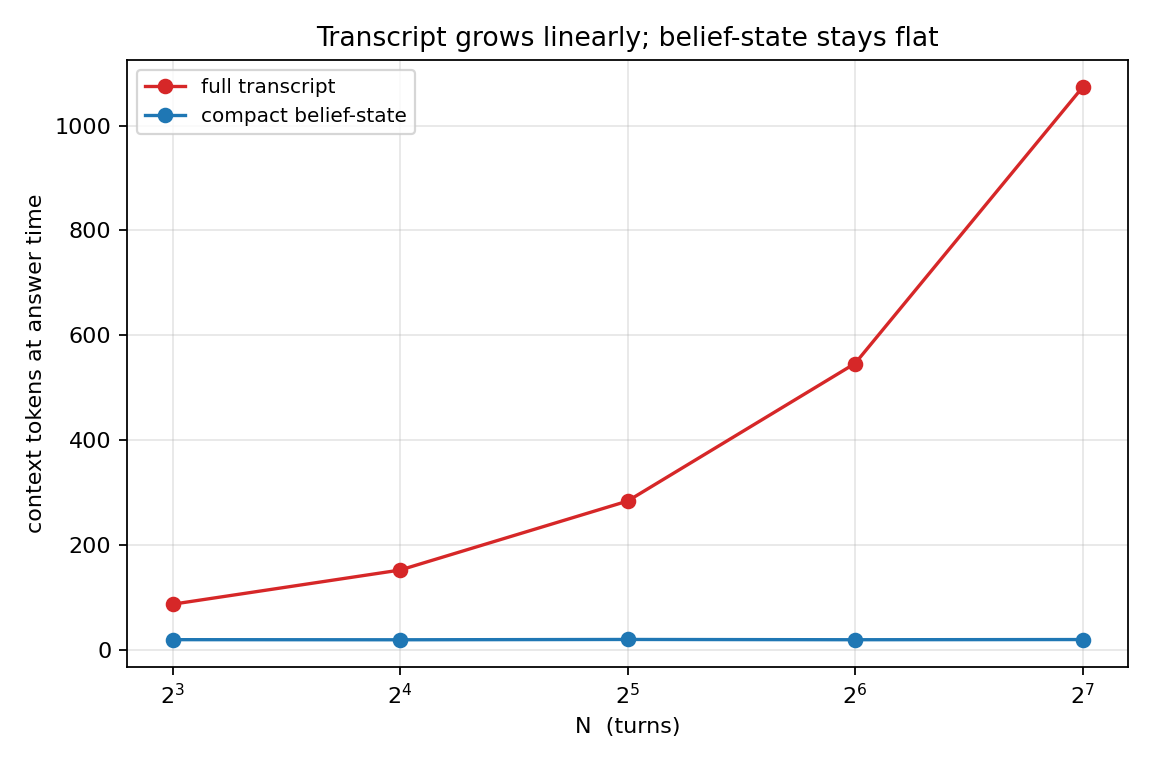
The experiment holds the model, the task, and the information fixed and varies only whether state is carried or re-derived, so the contrast is causal: the transcript's collapse is the cost of re-derivation, not of missing information, since the facts are present in both conditions. The magnitude depends on the model, a larger one with a longer effective context would rot later, but the direction does not, and re-derivation grows in exactly the quantity an agent accumulates without bound. The carried state here is a prompted summary standing in for a learned belief state, which makes the result a lower bound: even this crude mechanism closes the gap.
The strongest existing work makes the same move. MEM1 [5] trains an agent by reinforcement learning to keep a constant-size internal state that blends memory and reasoning, and reports gains over full-context prompting on long-horizon tasks. So a compact learned state is known to help. The contribution here is the framing: the belief state is one of the two learned objects a POMDP solver requires, the turn ceiling [1] and the horizon-dependent failures [2] are what a missing belief state looks like from outside, and the same diagnosis identifies a second missing object.
The second object is a value: a function that scores states or candidate answers so the agent can select among the ones it proposes. Search is propose-and-select. The agent proposes by sampling and, in best-of-\(N\), selects the highest-scoring candidate,
$$\hat{x} = \arg\max_{x_1, \dots, x_N \sim \pi} V(x_i).$$Training a verifier this way is how OpenAI first beat fine-tuning on grade-school math, where the verifier scaled better with data than enlarging the generator [3], and it is the engine under recent test-time-compute gains [4]. But next-token training does not produce \(V\). The only value an agent gets for free is its own sequence likelihood, and ranking by likelihood is just MAP decoding. The reason sampling helps at all is that the mode is often wrong, so the free verifier is the one verifier guaranteed to share the proposer's mistakes. Process reward models [6] and generative verifiers [7] are stronger, but they are fine-tuned from the same backbone on the policy's own rollouts, so their errors stay correlated with the policy's.
Selection beats a single sample only when the verifier ranks candidates differently from the proposer, which is to say only when its errors fall in different places. If the verifier's errors are perfectly correlated with the proposer's confidence, re-ranking re-selects what the proposer already preferred. To measure this I held a verifier fixed and varied only its coupling to the generator, mixing its score \(v\) with the generator's normalized log-likelihood \(s\):
$$V_\rho(x) = (1-\rho)\,\tilde v(x) + \rho\,\tilde s(x).$$# rank N candidates by a verifier dialed toward the generator's own confidence
def best_of_n(v, s, labels, rho, N): # v: verifier score s: gen log-likelihood
score = (1 - rho) * z(v) + rho * z(s) # rho = coupling to the generator
return labels[score[:N].argmax()] # 1 if the chosen answer is correct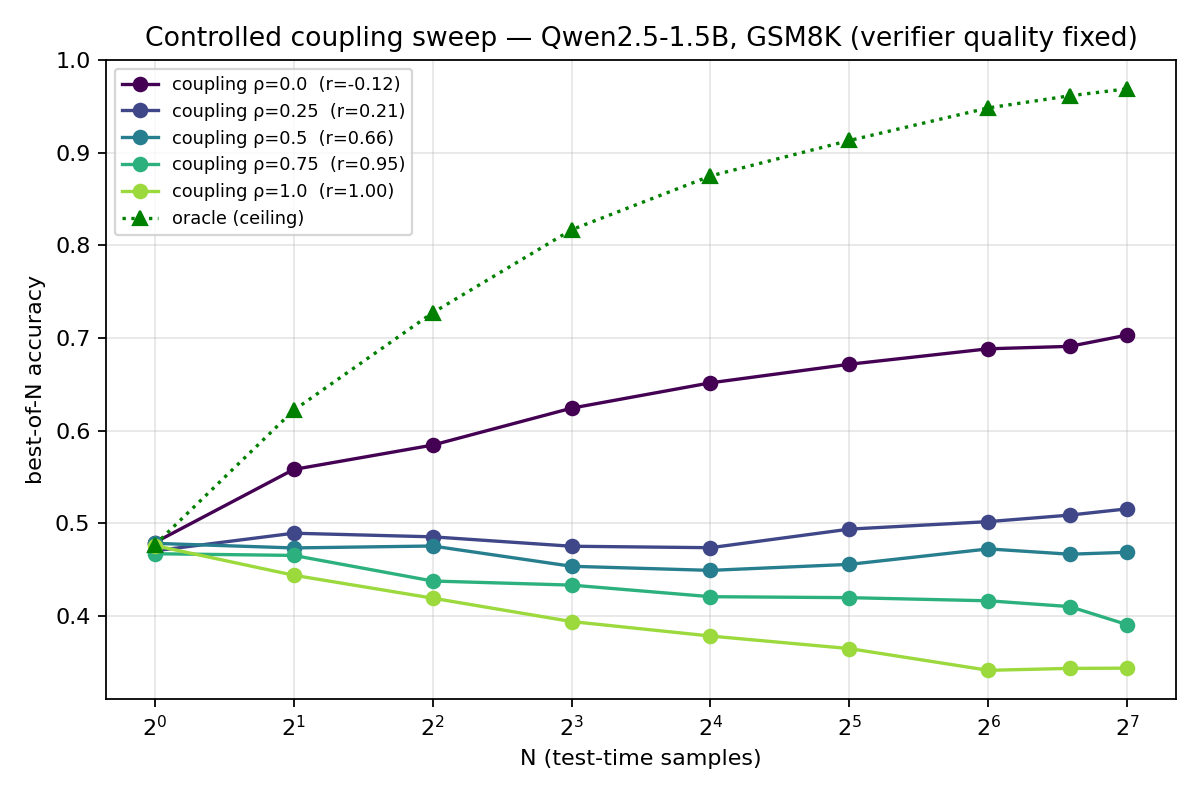
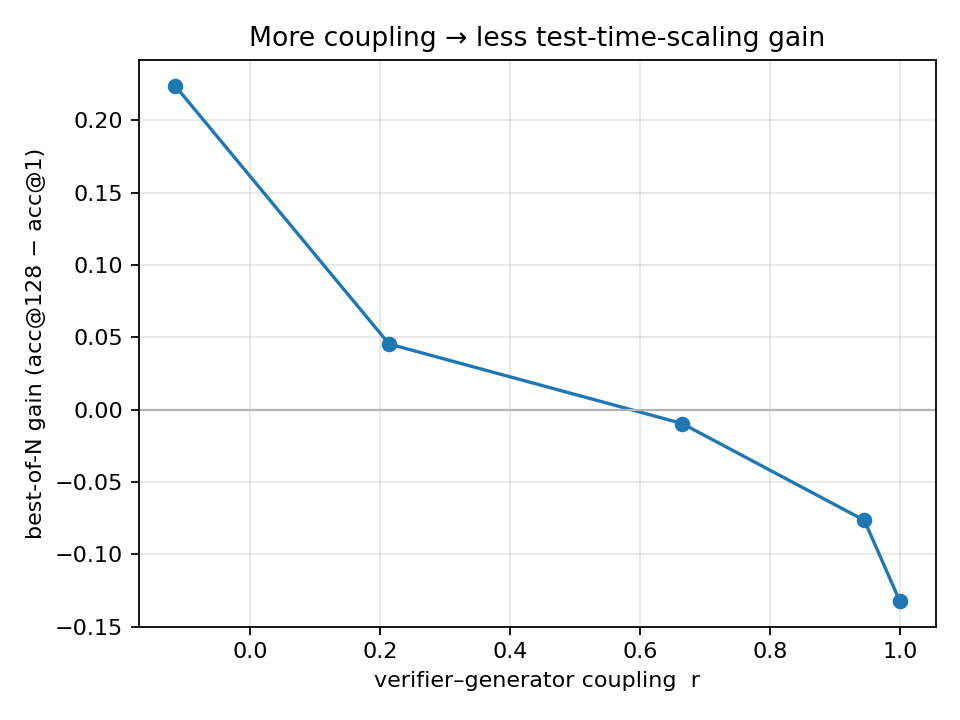
This is the actor-critic problem under another name. Sharing representation between a policy and its value function causes interference; Phasic Policy Gradient [8] separates them into distinct phases for exactly this reason, and decoupled actor and critic representations specialize while coupled ones degrade [9]. The same coupling caps test-time search. The field is converging on the fix: ARTS [10] disentangles verification from generation and recovers long-tail problems where coupled optimization collapses, and weak-verifier ensembles [11] work by combining judges whose errors are not aligned. A value, like a belief state, has to be its own object with its own errors.
The two experiments measure different failures, so treating them as one problem is an argument rather than a measurement. The argument is this. A model trained to continue text learns neither to maintain state nor to judge it; it learns to predict the next token. Post-training then asks it to do both with the only materials it has, the transcript and its own probability, and both substitutes fail with scale: the transcript rots with horizon, the value is coupled to the policy it is meant to check. Adding a verifier or a memory module afterward inherits the problem, because neither object was ever learned in the first place.
The implication is a training objective, not an inference trick. A foundation model for search would carry a learned belief state and an independent value, trained jointly with generation rather than added later,
$$\mathcal{L} \;=\; \underbrace{-\textstyle\sum_t \log \pi(x_t \mid x_{\lt t})}_{\text{generate}} \;+\; \lambda\,\underbrace{\mathcal{L}_{\text{state}}(b_t,\, o_{\le t})}_{\text{belief update}} \;+\; \mu\,\underbrace{\mathcal{L}_{\text{value}}(V,\, y)}_{\text{decoupled verifier}}$$where the belief loss trains a recurrent update that reconstructs the current state from a fixed-size carry, and the value loss trains a verifier on negatives drawn from outside the policy's own rollouts so its errors decorrelate from the generator's. This is close in spirit to a discriminative pretraining objective like ELECTRA [12], which trained a model to judge rather than generate and was abandoned when generation won the scaling race. In the search setting, where judging and state-tracking are the bottlenecks, that is the move worth revisiting. Read literally, reinventing search earlier than post-training means putting these two objects in the foundation.
I have not trained the foundational versions of either object; that needs a pretraining run rather than the controlled studies here. What these establish is the mechanism for both failures on real models, and that they are one failure: a search agent built on a text model has no state and no value, and faking them is why long-horizon search rots and test-time search saturates. If you are building search agents and think these can stay implicit, I would like to know where this breaks.
Setup. Belief-state study: Qwen2.5-1.5B-Instruct on a synthetic four-entity state-tracking task, horizons 8 to 128, transcript-conditioned answering vs. an incrementally updated compact state, accuracy and context measured at answer time. Coupling study: best-of-\(N\) on GSM8K with a fixed verifier whose score is mixed with the generator's normalized log-likelihood to vary coupling while holding quality fixed. Code and data: github.com/ShreshthRajan.