Shreshth Rajan, April 2026.
In summer 2024, I realized codebase understanding was a bottleneck to engineering in large organizations. New engineers spend weeks or months building a mental model of a system before they can ship anything. Senior engineers carry that model in their heads and can't easily hand it off. I tested different formats with peers, and a graph-based view turned out to be the most digestible way to hold a codebase in your head. That became Visdep.
Two years later, the field has caught up. Context graphs, code maps, and agentic navigation are active research directions. Cognition's DeepWiki generates architecture diagrams, module summaries, and dependency maps with a natural-language Q&A interface. Their Windsurf Codemaps (Oct 2025) goes further: task-specific structured maps humans navigate to understand code, which agents can also reference via @{codemap}. Devin Review (April 2026) applies the same pattern to pull request review, piping diffs into Devin sessions with full codebase context and flagging issues by severity. Aider's repo map uses tree-sitter parsing and PageRank to produce a token-budgeted graph of a codebase for agents. The Navigation Paradox paper (Feb 2026) shows graph-structured dependency navigation outperforms retrieval on architecture-heavy tasks. I made some updates to the original project and am leaving it free. What follows is how I think about the problem.
The retrieval field has spent the last year arguing about indexes. Anthropic replaced pre-built RAG with agentic grep in Claude Code. GrepRAG (Feb 2026) beat graph-based methods by 7-15% on completion benchmarks. Cognition trained SWE-grep for fast parallel tool calls. Cursor ships tree-sitter chunking, a vector DB, and a 7B reranker. The direction of travel is clear: static pre-built indexes are losing to lexical search and agentic exploration.
This is the right direction for generation. It's the wrong frame for understanding. Completion and understanding are not the same problem.
Completion is a local, iterative, generative problem. You want the minimum context to produce the next token. Grep is perfect for that: fast, exact, cheap to iterate. The deeper reason grep wins here is course-correction. If the first query returns the wrong function, the agent queries again with refined terms. Pre-built RAG stuffs context upfront. If the retrieved set is wrong, you can't course-correct without re-running the pipeline. Understanding is a different problem. It is global and structural. You want the shape of the system: dependencies, layers, invariants. Grep cannot find the shape of a graph by searching its vertices.
The Navigation Paradox paper measured this directly. Context windows hit 1M tokens this year and some expected that to kill retrieval entirely. It didn't. Anthropic's team documents the reason as "context rot" in their context engineering post: as tokens fill the window, model precision at using any specific token decays. In the Navigation Paradox experiments, even with all of Claude Code's context available, architecturally distant files never got pulled in. The fix was exposing static dependency edges (imports, inheritance, instantiation) as a navigation tool. Graph-structured navigation outperformed retrieval on every architecture-heavy task. Bigger windows remove retrieval as a capacity constraint. They leave it as a navigation problem.
So the frontier labs have split their systems correctly by problem type, even if the shared framing is muddy. Cursor and Claude Code optimize for moment-to-moment retrieval during generation. DeepWiki and Codemaps produce persistent, shareable artifacts humans navigate and agents can reference. The piece still missing is bidirectionality. In the current generation of tools, the artifact informs the model and informs the human, but edits to the artifact do not propagate back to the code.
Figure 1. The impact set of one function grows non-linearly with hop distance. Grep finds the center. Only a graph finds the set.
The deeper point is that understanding is not a Q&A transaction. It is a structured object that humans build over time.
When a senior engineer understands a codebase, what they have is a graph: this layer calls that one, this class holds state for those methods, this module is on the hot path. They update it when the code changes. They use it to explain, to debug, to onboard others. The graph is the understanding.
Most AI systems produce answers. The user asks, the model responds, and the structure dissolves back into tokens the moment the conversation ends. DeepWiki and Codemaps are further along. Codemaps in particular are explicitly "shareable artifacts that bridge the gap between human comprehension and AI reasoning," generated per-task and referenceable by agents. That is the right shape.
What none of the current generation does yet is close the loop. The artifact is read-only with respect to the code: you can query it, share it, feed it to an agent, but you cannot edit the artifact and watch the code update. The version that matters treats the graph as both interface and source of truth. Citations in any answer are nodes you can click through. Edits to a node edit the code. In that version the artifact becomes the output, and retrieval is a side effect of producing it.
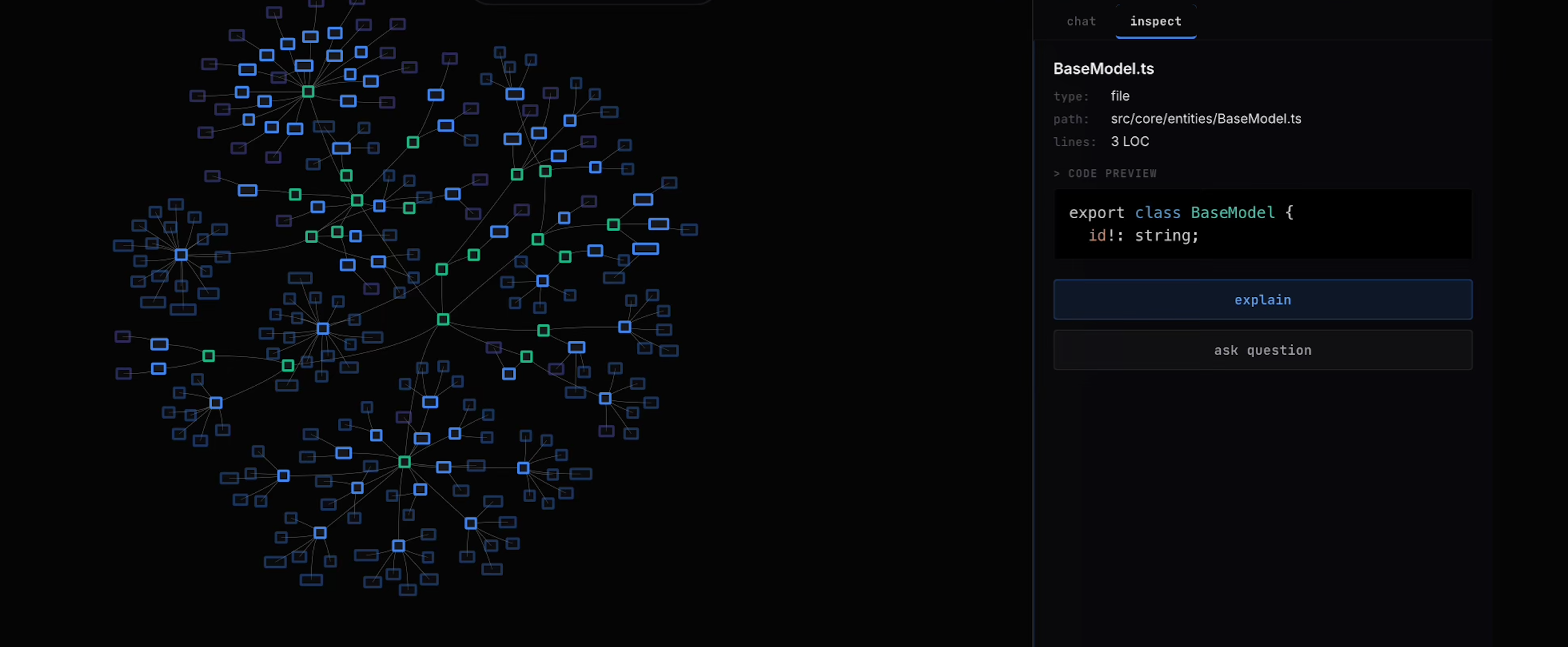
Visdep is the small version of this argument. It treats the method-level dependency graph as the primary interface. You navigate the graph, ask questions, and see which nodes the model used. Retrieval runs underneath but the interface is the graph, not the chat window.
Visdep is built on the current standard retrieval stack for code: hybrid lexical and dense via RRF, 3-hop graph expansion with PageRank, MiniLM cross-encoder reranking, budgeted context. Three things distinguish it. Method-level nodes instead of files: a class with five methods is one chunk in most systems and five chunks here. User-driven navigation matters more than I expected. Humans keep their own model of the system when they are driving and lose it when they are not. Citation highlighting on the graph instead of inline footnotes: you can see what the model used, what it ignored, and decide whether to trust the answer.
Code already lives in compiler-friendly trees, language-friendly modules, IDE-friendly files, git-friendly commits, and now embedding-friendly chunks. Each was designed for a different reader. Visdep adds one more layer. Compilers have had structural understanding of code since the 1950s, and we are doing RAG over what was already a parse tree. The question I keep circling is whether the next interesting move is another layer, or reimagining from below.
Figure 2. The Visdep pipeline.
Responses cite file:line references. Cited nodes light up on a rendered method-level graph. You can drag methods into the chat context. End-to-end latency is 2-3 seconds on repos with 100K+ chunks.
Figure 3. Visdep UI. Selecting a node reveals file path, line count, code preview, and options to explain or ask questions about that code. Try it at visdep.com.
The benchmarks are catching up. SWE-bench Verified is saturating at 87.6% for Claude Opus 4.7, and the field is quietly moving past it. The harder benchmarks built in the last six months test long-horizon, multi-file reasoning instead of single-issue fixes. SWE-EVO (Jan 2026) is the sharpest case: GPT-5.4 with OpenHands scores 25% on tasks requiring multi-step modifications across an average of 21 files. The same family of models scores in the 70s on SWE-bench Verified. The roughly 50-point gap is the cost of moving from single-issue fixes to sustained multi-file reasoning. SWE-Bench Pro, SWE-Lancer, and SWE-rebench point the same direction. The gap between bug-fix accuracy and sustained codebase reasoning is where understanding lives.
Pure vector-only retrieval for code is a solved dead end. Identifiers are exact-match artifacts, not fuzzy semantic ones, and every serious system in 2026 either uses hybrid retrieval or skips pre-built indexes entirely. The interesting frontier is further up the stack. Three directions matter.
Git-native graphs. Modern indexers detect file changes incrementally (Cursor uses a Merkle tree that syncs every few minutes) but don't treat the graph diff between commits as a first-class semantic signal. A function whose 3-hop neighborhood changes is a function whose meaning probably changed. A PR whose graph diff touches unrelated subgraphs is probably doing too much. These are measurable properties that could become part of how PRs get routed, reviewed, or flagged, and nobody is building them yet.
Learned edges from runtime and history. The edges current systems use (imports, inheritance, explicit calls parsed from the AST) are the easiest to compute and the least informative. Mining git history for co-change is not new. Zimmermann and colleagues established the approach in "Mining Version Histories to Guide Software Changes" (ICSE 2004), and there is two decades of follow-on work in the software engineering literature. What is new is treating those edges as first-class retrieval signals for LLMs, fused with trace and CI co-failure signals under learned weights. The graph that predicts engineering behavior is empirical:
Each lives in artifacts every serious company already has: Datadog traces, CI logs, git history, incident reports. Nobody has fused them into a retrieval graph under learned weights. The obvious failure mode is greenfield code, where there's no history to mine. The empirical graph supplements the static graph; it doesn't replace it.
Figure 4. Static edges are a thin slice of the real graph. Most of what engineers know about their codebases comes from edges no current system tracks.
The cleaner version of this research is a benchmark. SWE-EVO and RefactorBench get partway by testing multi-file reasoning, but the test I want does not exist yet. Call it blast-radius prediction: given a diff, predict the set of tests that will fail, the modules that will need updating, and the historical incidents most structurally similar. The term comes from DevOps and impact-analysis tooling, where it's been in use for a decade; the contribution would be formalizing it as a quantitative LLM benchmark with ground truth mined from CI logs and incident postmortems. Devin Review is the closest shipped product in this direction, but it's scoped to bug detection on individual diffs. No open benchmark measures blast-radius prediction as a quantitative task, which is what would cleanly separate architectures that model the empirical graph from those that rely on lexical exploration alone.
Editable artifacts. The current model is ask → answer → dissolve. The next is navigate → edit → propagate. The graph the user traverses is the same graph the model reasons over. Citations are clickable. Edits to a node are edits to the code. This collapses the gap between reading and writing that every current tool maintains. The reason this hasn't shipped yet is probably engineering debt rather than research debt: round-tripping graph edits to AST mutations needs a parser that's effectively invertible, conflict resolution for concurrent edits, and a way to handle changes that don't have a clean code-level representation. None of these are theoretical problems. Nobody has scoped them.
Pre-built static retrieval is mostly solved. Agentic retrieval is being solved now. Persistent artifacts are a partially solved problem (DeepWiki, Codemaps, Aider's repo map). What remains open is the part I find most interesting: the edge weights that make those artifacts predictive of real engineering behavior, the benchmarks that would prove them out, and the loop that makes them editable.